





























Chapter 1. Technical description
37
Caches also improve performance because they reduce queuing time of
accesses that miss the caches and require a physical memory access.
For most commercial applications, cache hit rates are usually greater than 70
percent. In this case, the cache greatly reduces memory latency because
most processor memory requests are serviced by the faster cache. The
caches act as filters and reduce the load on the memory controller, which
results in lower queuing delays (waiting in line) at the memory controller,
thereby speeding up the average memory access time.
Another bottleneck in many SMP systems is the front-side bus. The front-side
bus connects the processors to the shared memory controller.
Process-to-memory requests travel across the front-side bus, which can become
overloaded when three or more high-speed CPUs are added to the same bus.
This, in turn, leads to a performance bottleneck and lower system scalability.
Large processor caches also help improve performance because they assist in
filtering many of the requests that must travel over the front-side bus (a processor
cache-hit does not require a front-side bus for memory transaction).
However, even with a large L3 cache, the number of memory transactions that
miss the cache is still so great that it often causes the memory controller to
bottleneck. This happens when more than three or four processors are installed
in the same system.
Non-uniform Memory Access (NUMA) is an architecture designed to improve
performance and solve latency problems inherent in large (greater than four
processors) SMP systems. The x455 implements a NUMA-based architecture
and can scale up to 16 processors using multiple servers.
The servers each contain up to four CPUs and 28 memory DIMMs. Each servers
also has a dedicated local Cache and Scalability Controller, Memory Controller,
and 64 MB XceL4 Level 4 cache. The additional fourth level of cache greatly
improves performance for the four processors in the server because it is able to
respond to a majority of processor-to-memory requests, thereby reducing the
load on the memory controller and speeding up average memory access times.
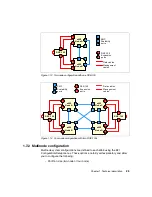
As shown in Figure 1-12 on page 23, each server is connected to another server
using three independent 3.2 GBps scalability cables. These scalability cables
mirror front-side bus operations to all other servers and are key to building large
multiprocessing multinode systems.
By mirroring transactions on the front-side bus across the scalability links to other
processors, the x455 is able to run standard SMP software. All SMP systems
must perform processor-to-processor communication (also known as “snooping”)
to ensure that all processors receive the most recent copy of requested data.
Since any processor can store data in a local cache and modify that data at any
Summary of Contents for 88553RX
Page 2: ......
Page 214: ...200 IBM Eserver xSeries 455 Planning and Installation Guide Figure 5 14 Connect to the x455...
Page 228: ...214 IBM Eserver xSeries 455 Planning and Installation Guide...
Page 229: ...IBM Eserver xSeries 455 Planning and Installation Guide...
Page 230: ......
Page 231: ......







































































