

















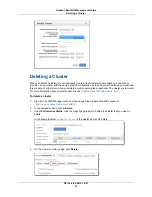






When creating a cluster you can optionally choose the cluster encryption option for additional security.
When you enable encryption in your cluster, Amazon Redshift stores all data in user-created tables in an
encrypted format. Note that enabling encryption in your cluster will impact performance, even though it
is hardware accelerated. On average, we expect you will see approximately a 20% degradation, with
peak overheads of 40%. You should take this into account when deciding whether you should enable
encryption when you create the cluster. Encryption is an immutable property of the cluster. The only way
to go from encrypted to non encrypted or vice versa is to unload the data and reload it to a new cluster.
Encryption also applies to backups. When restoring from an encrypted snapshot, the new cluster will be
encrypted as well.
If you are using the Amazon Redshift console to provision a cluster, it provides values for these options
for you to choose from. If you are provisioning a cluster programmatically, you can use the Amazon
Redshift API to find available options such as available node types Availability Zones (AZ) in which the
node types are available.
Note
At this time Amazon Redshift version 1.0 engine is available, however, as the engine is updated,
multiple Amazon Redshift engine versions might be available for selection.
For a list of supported AWS regions where you can provision a cluster, go to the
Regions and Endpoints
section in the Amazon Web Services Glossary.
How Many Nodes Do I Need?
When you provision a cluster, you specify the type and the number of nodes that you need. You have a
choice of two node types when provisioning your own cluster, an extra large node (XL) with 2 TB of
compressed storage or an eight extra large node (8XL) with 16 TB of compressed storage. A cluster can
consist of a single XL node, or it can be as large as a 100 8XL nodes. XL clusters can contain from 1 to
32 nodes; 8XL clusters can contain 2 to 100 nodes. For pricing information and detailed information about
individual node types, go the Amazon Redshift
product detail page
.
The number of nodes you choose depends on the size of your dataset and your desired query performance.
For example, if you have 32 TB of data, you can choose 16 XL nodes or 2 8XL nodes. If your data grows
in small increments, choosing XL nodes will allow you to scale in increments of 2 TB. If you typically see
data growth in larger increments, an 8XL node based cluster may be a better choice.
Because Amazon Redshift distributes and executes queries in parallel across all Compute Nodes, you
can increase query performance by adding nodes to your data warehouse cluster. Amazon Redshift also
distributes your data across all compute nodes in a cluster. When you run a cluster with at least two
compute nodes, data on each node will always be mirrored on disks on another node and you reduce
the risk of incurring data loss.
Whichever choice you make, you can monitor query performance in the Amazon Redshift Console and
with Amazon Cloud Watch metrics.You can also add or remove nodes, as needed, to achieve the balance
between storage and performance that works best for you. When you request an additional node, Amazon
Redshift takes care of all the details of deployment, load balancing, and data maintenance.
For pricing information and detailed information about individual node types, go the Amazon Redshift
product detail page
.
Availability Zone Considerations
By default, Amazon Redshift provisions your cluster in a randomly selected Availability Zone (AZ) within
the AWS region that you specify. All the cluster nodes are provisioned in the same AZ.
You can optionally request a specific Availability Zone, if Amazon Redshift is available in that Availability
Zone. For example, if you already have an Amazon Elastic Compute Cloud (EC2) instance running in
one Availability Zone, you might want to create your cluster in the same Availability Zone to reduce latency.
API Version 2012-12-01
5
Amazon Redshift Management Guide
How Many Nodes Do I Need?







































































