





























Interlocked Operations
7-18
The ’C3x code for V(S) is shown in Example 7–10; code for P(S) is shown in
Example 7–11. Compare the code in Example 7–11 to the code in Example 7–9,
which does not use semaphores.
Example 7–10. Implementation of V(S)
V:
LDII
@S,R0
; Interlocked read of S begins (XFO = 0)
; Contents of S
→
R0
ADDI
1,R0
; Increment R0 (= S)
STII
R0,@S
; Update S, end interlock (XF0 = 0)
Example 7–11. Implementation of P(S)
P:
OR
4,IOF
; End interlock (XF0 = 1)
NOP
; Avoid potential pipeline conflicts when
; executing out of cache, on-chip memory
; or zero wait-state memory
LDII
@S,R0
; Interlocked read of S begins
; Contents of S
→
R0
BZ
P
; If S = 0, go to P and try again
SUBI
1,R0
; Decrement R0 (= S)
STII
R0,@S
; Update S, end interlock (XF0 = 1)
The SIGI operation can synchronize, at an instruction level, multiple ’C3xs.
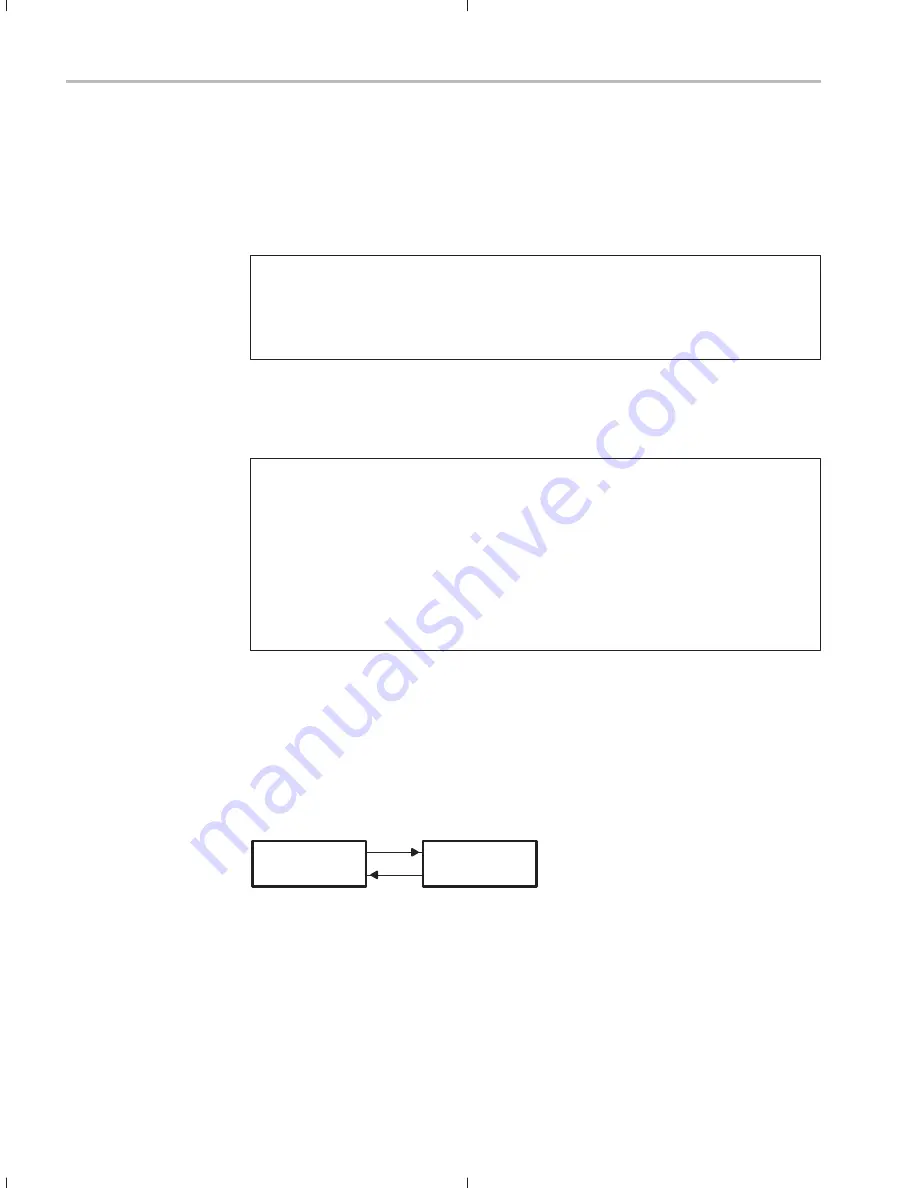
Consider two processors connected as shown in Figure 7–3. The code for the
two processors is shown in Example 7–12.
Figure 7–3. Zero-Logic Interconnect of TMS320C3x Devices
XF0
XF1
XF1
’C3x #1
’C3x #2
XF0
Processor #1 runs until it executes the SIGI. It then waits until processor #2
executes a SIGI. At this point, the two processors are synchronized and continue
execution.







































































