






















Copyright © 2006 MCA Internet, LLC dba BERTL.
13 November 2006
All Rights Reserved. The license under which this document is made available and applicable law prohibit any reproduction or further transmission of any portion of this document. This
document may only be viewed electronically through the www.BERTL.com Web site and may not be stored in electronic or hard copy format. Any reproduction of trademarks is strictly
prohibited. BERTL accepts no responsibility for any inaccuracies or omissions contained in this document.
Page 41
Ricoh Aficio MP1350
Scan Data Capture Accuracy
One of the fastest growing needs for high-
speed scanning is the conversion of legacy
hard copy documents into an electronic
format for better information sharing, reduced
storage space, and easier search and data retrieval.
A scan converts a page into an image, which is not very
manageable. Most companies use optical character
recognition (OCR) software to convert the images into
editable text, which can then be searched, changed, or
incorporated into a new document as required.
The OCR engine recognizes individual images on the
page, converting them into letters, numbers, and other
symbols. The OCR engine then runs complex analysis on
the text in conjunction with spell checkers, technical
dictionaries, and other data sources before offering up its
best conversion into electronic format.
This stage can be very time-consuming, especially if the
quality of the scanned data is poor. This leads to character
recognition errors.
To look into this important workflow issue, BERTL ran a
series of standard test patterns with multiple font types,
sizes, and colors capturing the data at various resolutions
using both text and text/photo settings. Text is the default
setting for most OCR work due to its 2-bit format, which
tends to produce the best text reproduction.
However, as more documents incorporate images and
color elements, text/photo, which operates in 8-bit and
reproduces gray shades for better reproduction of images
and colored text elements, is also being used.
After scanning each page of its test originals, BERTL
analysts then ran the scanned files through ABBYY
FineReader 8.0, in default configuration. The impact of the
accuracy of the scanning process at the various resolutions
and settings is reflected in the number of manual
confirmations that the OCR application demands before
the document is deemed clean and ready to use.
The higher the human intervention rate, the higher the cost
of carrying out the action. As expected, the greatest
difficulty in OCR recognition was found on the smallest 4
point text sections of the test documents.
The choice of OCR application will also have a dramatic
effect on the level of human intervention that is required
after the initial scanning has taken place. For that reason,
we have standardized on ABBYY, a well-respected leading
OCR software developer.
Our tests are run using the latest level of ABBYY’s
FineReader 8.0 software in Default modes. Through fine
tuning of the rich feature set in ABBYY, an additional
portion of the manual intervention could be removed.
However, to maintain benchmark comparison procedures,
default settings were selected.
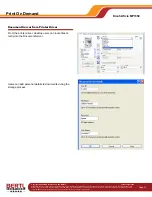
Above is a portion of BERTL’s OCR test chart scanned at
200 dpi (top), 300 dpi (middle), and 600 dpi (bottom) in text
format and saved as a PDF file. The image has been
zoomed to 400 percent in Adobe Acrobat and screen-
captured for display.
The top line is 4 point, the middle line is 6 point, and the
bottom line 8 point.
Scan







































































