











7
Memory Mirroring
Continuous operation even in the event of a non-correctable memory error
The Express5800/1000 series server supports high-level memory
RAS features to ensure that the server can rapidly detect memory
errors, reduce multi-bit errors and continually operate even in
the event of memory chip or memory controller failures. Memory
scan, memory chip sparing (SDDC*) and memory scrubbing are
examples of those features.
A memory scan is run on all loaded memory modules at each OS
boot. If the system detects a memory failure, the failed component
is immediately isolated and detached from the system preventing
possible downtime during business operations.
Chip sparing (SDDC*) memory is a memory system loaded with
several DRAM chips that can correct errors at the chip level. If
a failure were to occur in the memory, the error can be corrected
immediately to allow for continuous operation.
Memory scrubbing checks memory content regularly (every few
milliseconds) during operation without affecting performance.
When an error is detected, it is corrected and then reported.
The scrubbing function is effective in detecting errors in a timely
manner which ultimately results in the reduction of multi-bit errors.
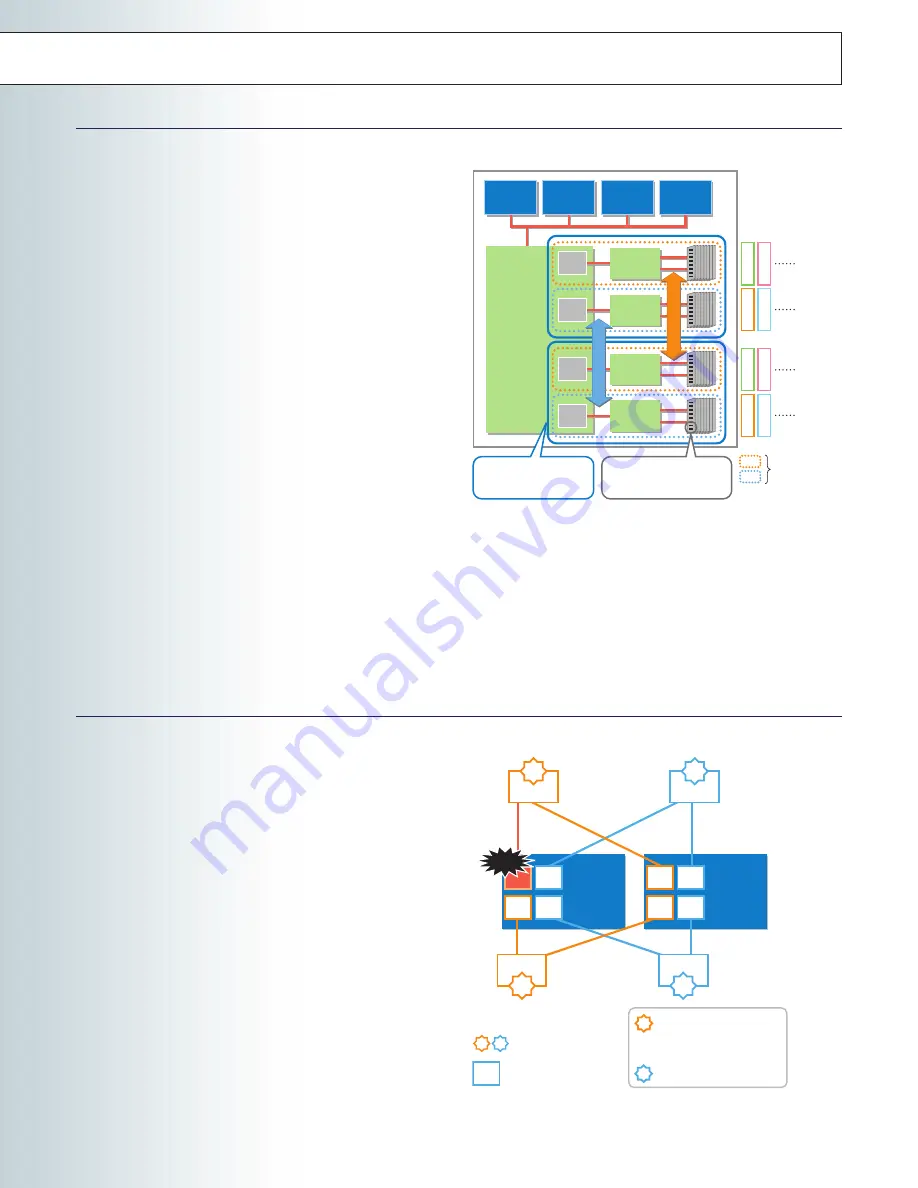
Memory mirroring takes place continuously, where the same data
is written onto 2 separate memory blocks instead of 1 (available
only on the 1160Xf and 1320Xf). In the event of a non-correctable
error, due to the fact that the data exists on two independent
blocks, operations are able to continue without interruption.
Partial Chipset degradation
Avoid multi-partition shutdowns resulting from chipset failures
In certain instances when multiple server partitions share a
common crossbar controller, effects of a single partition failure
may result in a multi-partition shutdown. To resolve this issue, the
Express5800/1000 series servers have been designed to allow for
the partial degradation of chipsets.
Within each of the LSI chips, which make up the chipset, multiple
LSI sub-units exist. These sub-units are connected to other sub-
units located on separate LSI chips. The combined sub-units
together make up single partition. If an error were to occur on an
LSI sub-unit, that sub-unit alone can be degradated to isolate the
failure to a single partition, thus preventing the failure to spread to
other partitions.
Furthermore, the downed partition can automatically reboot
itself, after isolating the failed subsystem, to resume operations
in a degradated mode without the intervention of a system
administrator. This is made possible, on the Express5800/1000
series servers, by the redundant paths between the Cells and the
IO.
Memory
Image
Unit of degradation
on the Express5800/
1000 Series
D
at
a
0
D
at
a
2
D
at
a
1
D
at
a
3
D
at
a
0
D
at
a
2
D
at
a
1
D
at
a
3
Cell
Controller
Memory
I/F
Memory
Controller
Memory
I/F
Memory
Controller
Memory
I/F
Memory
Controller
Memory
I/F
Memory
Controller
Components covered by
the memory mirroring
CPU
CPU
CPU
CPU
M
ir
ro
r
M
ir
ro
r
Components covered by
the standard chip sparing
PCIBox
0
0
PCIBox
1
1
0
1
Sub
Unit
Sub
Unit
Crossbar
Controller
A
Sub
Unit
Sub
Unit
Crossbar
Controller
B
Sub
Unit
Sub
Unit
Sub
Unit
Sub
Unit
Sub
Unit
Cell 1
1
Cell 0
0
Partial
degradation
Failure
n specifies the partition number
Sub-units within the chipset
Additional sub-sets exist in
actuality
Not affected
Failure occurs at the sub-unit of
the crossbar controller.
Partition 0 is shutdown so that the
failed component can be isolated.
Partition 0 is rebooted
This construct allows for continuous operation through all non-
correctablememory errors, not limited to the memory themselves,
but also in the memory interfaces and the in memory controllers.
* Single Device Data Correction







































































